Global EN
Soham Biswas
Lead Technology , Montreal, Canada
Data
Data modeling is essential for structuring and organizing databases effectively. It maps out the types of data stored within a system, illustrates relationships between data types, and outlines their attributes and formats. In SQL, data modeling underpins database design, ensuring that data is stored logically and can be accessed efficiently.
This article is an introductory 101 with a focus on OLAP (Online analytical processing) data modelling formats; mainly used for data warehousing and multi-dimensional analysis. OLTP (Online transaction processing) modelling differs slightly, putting more emphasis on speed and volume for data updates rather than being optimised to run complex analytics queries.
Conceptual models provide a high-level view of system elements, focusing on business processes and how data is organized without delving into technical specifics.
Logical models provide a deeper level of detail when compared to conceptual ones by defining specific data entities, their attributes, and relationships.
And finally, physical models offer a concrete and specific representation of a system’s implementation within a database. They detail how data is stored, indexed, and accessed, providing a blueprint for the actual database structure and operations.
Dimensional modeling (DM) is a data modeling technique that’s part of the Business Dimensional Lifecycle methodology developed by Ralph Kimball. It involves a set of methods, techniques, and concepts for designing data warehouses and aims to organize and structure data in a way that facilitates efficient querying and analysis. Moreover, it's particularly useful when dealing with large volumes of data and when users need to explore data from different angles.
This modeling approach structures data into two main types of tables: Fact tables and dimension tables. Fact tables contain the core numeric data — such as business metrics — which are typically linked via foreign keys to dimension tables.
These dimension tables provide essential context, storing descriptive data that aids in analyzing the metrics from the fact tables. For instance, dimension tables might include details on time periods, product information, or geographic data, which are pivotal for comprehensive analysis. Each dimension table includes a primary key that uniquely identifies it's records, facilitating a clear and efficient indexing system. This setup ensures that data across tables can be matched and retrieved effectively using these keys, which are fundamental to maintaining the database's structural integrity and query speed.
It’s important to remember that when handling data that may evolve over time, the schema of the tables must be optimized to handle the required types of historical changes. Six main techniques can be used to achieve this. These techniques are called Slowly Changing Dimensions (or SCDs), the SCD2 and SCD6 being the most used in data warehousing for analysis purposes. Stay tuned for a future article detailing the different types of SCDs and when to use which.
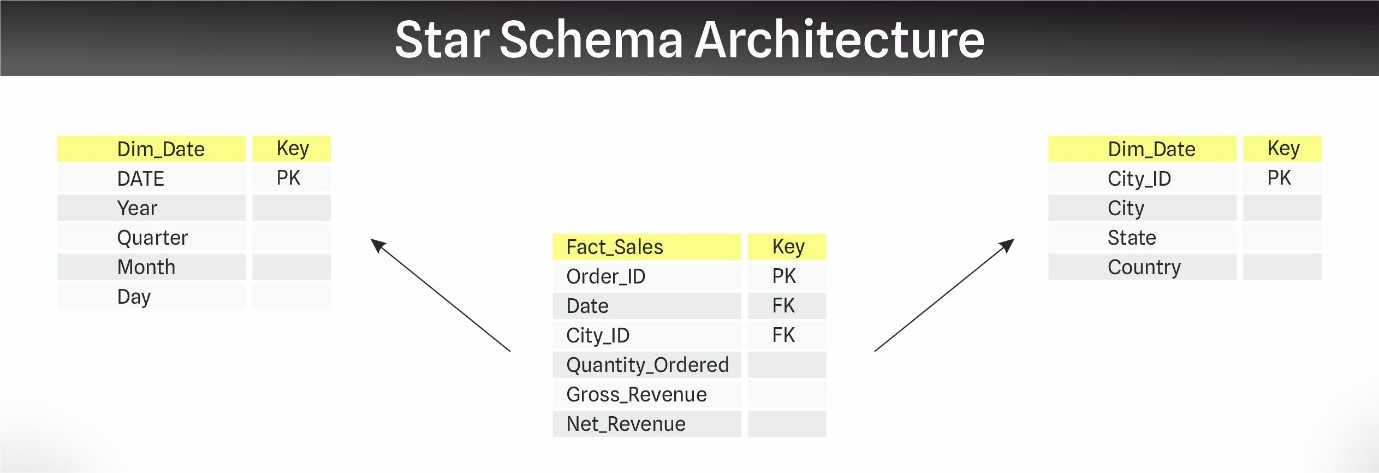
As we continue discussing data modeling strategies, It’s worth turning our attention to the two most common data modeling architectures: Star Schema and Snowflake Schema. Each of them has it's unique strengths and fits specific use cases.
The Star Schema features a central fact table surrounded by dimension tables, directly linked to the fact table without intermediary tables – as it's name suggests, it looks like a star when visualized. This configuration simplifies the data model and reduces the complexity of queries, making it easier for users to understand and for systems to retrieve data quickly. The primary advantages of using a Star Schema include simplified querying due to fewer joins, faster performance from efficient indexing, and intuitive data analysis.
However, it also has downsides such as potential data integrity issues due to denormalization, which can lead to redundancy and outdated information, as well as increased costs and limited flexibility – all of which cause hurdles with maintenance.
Despite these challenges, the Star Schema is particularly effective when quick, straightforward data access is prioritized over complex transformations. Additionally, it can also be used when users have a very clear understanding of the required data, when the data is structured and quantitative, or when data redundancy will not be an issue.
In contrast, the Snowflake Schema expands on the Star by normalizing dimension tables into multiple related tables. This reduces data redundancy and improves data integrity, however, that does come at the cost of increased complexity.
Queries in a Snowflake Schema involve more joins, which can slow down data retrieval. That said, this schema excels in managing more complex and dynamic dimensions with multiple levels of hierarchy. It’s suited for situations where data integrity and detailed dimensional analysis take precedence over simplicity and query speed.
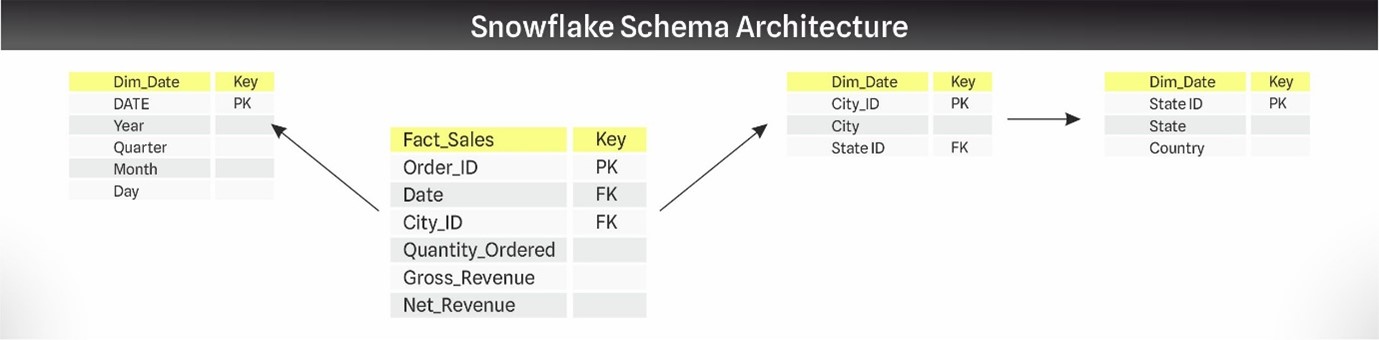
Deciding between the Star and Snowflake Schemas depends on the specific needs of your data warehousing project. Opt for the Star Schema if rapid querying and ease of use are paramount. Choose the Snowflake Schema when your priorities are flexibility, data integrity, and accommodating complex hierarchical data structures.
However, while it's important to make an informed decision based on your immediate needs, don’t shy away from experimenting and testing different configurations. Sometimes, the only way to truly understand what works best for your situation is through trial and refinement.

Lead Technology
Soham is a Technology Lead, who is associated with Synechron Canada since November 2023. He has over 10 years of experience in Data Analytics, Data Engineering & Data Science. He has worked across multiple geographies starting from India, France, MENA and presently working in Canada.
Additionally, Soham has worked across industries ranging from Fortune100 clients to unicorn startups.
He has worked across domains such as - Healthcare GSK in Wipro, BFSI & General Ledger Accounting, Ecommerce startups, CPG Consulting, OTT Platform (Netflix competitor) & Short Video Content App, Marketing Agencies, Procurement in Loblaws and in Capital Markets for Synechron.
Lastly, Soham has a Bachelor's in Engineering in India and Masters in International Finance in Europe.
Also, he have professional certifications in Tableau Desktop, PowerBI-DA100, CSPO (Certified Scrum Product Owner) from Scrum Alliance, etc.
 Australia
Australia  Canada
Canada  Canada
Canada  France
France  Hong Kong
Hong Kong  India
India  Japan
Japan  Luxembourg
Luxembourg  Saudi Arabia
Saudi Arabia  Serbia
Serbia  Singapore
Singapore  Switzerland
Switzerland  The Netherlands
The Netherlands  United Arab Emirates
United Arab Emirates  United Kingdom
United Kingdom  United States
United States